
Last week, a large and expertly run espionage operation was made public — one that began no later than October 2019, and which had been actively exploiting victims since at least early 2020. This incident is particularly interesting for several reasons: for the breadth of sensitive global government and industry targets, for misuse of a trusted product’s software supply chain, and for the techniques used to circumvent internal controls and maintain persistent access without raising alarms.
First, and most importantly, we feel deeply for incident responders, PR teams, security and technology professionals, attorneys, law enforcement, and others who will be dealing with investigations into their own systems as the result of these revelations instead of enjoying the holidays after a tough year. HugOps to all of you working hard to understand what happened and for cleaning it up!
What follows is our perspective on what happened based on the facts available so far, with some recommendations of what to focus on, and what not to lose focus of, as the dust settles.
What Happened?
Overview
FireEye reportedly discovered this campaign as they investigated a breach of their own network, and determined that it originated from a attacker modified version of SolarWinds’ Orion Product. They were far from the only ones impacted.
SolarWinds Orion is a network monitoring and management tool that is used widely to understand and control the complexity of heterogeneous environments. It needs broad and privileged access to function properly, and this makes it a great vehicle to gain access to many environments. To better illustrate this level of network access, we’ve outlined the scenario in a diagram below. Orion is represented by the system on the left, and on the right it is accessing cloud services, routers, workstation, software as a service offerings, and many other things an organization depends upon.
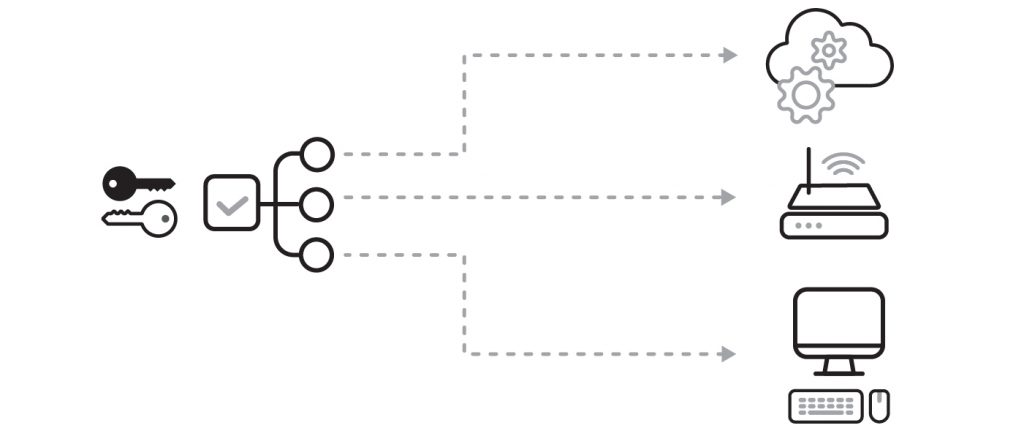
SolarWinds reported to the SEC that more than 18,000 Orion customers received the same infected update. While almost two thousand unique command and control domains are known for this malware, only a small percentage of organizations are confirmed impacted so far.
Gaining initial access via Orion
So far, little information is available about how Solarwinds came to be compromised, but we expect that to change over time. What we do have are details about how Orion came to have malicious code inserted.
The version of Orion containing the malicious payload came with a valid signature from SolarWinds’ software signing keys, and according to SolarWinds, the illicit modification happened in their software build system, and was not visible in their source code.
A software supply chain consists of all the people, systems, and code that go into making and distributing or operating a product, application, or service. A simplified version is illustrated here, showing roughly where the attack took place inside SolarWinds’ systems.
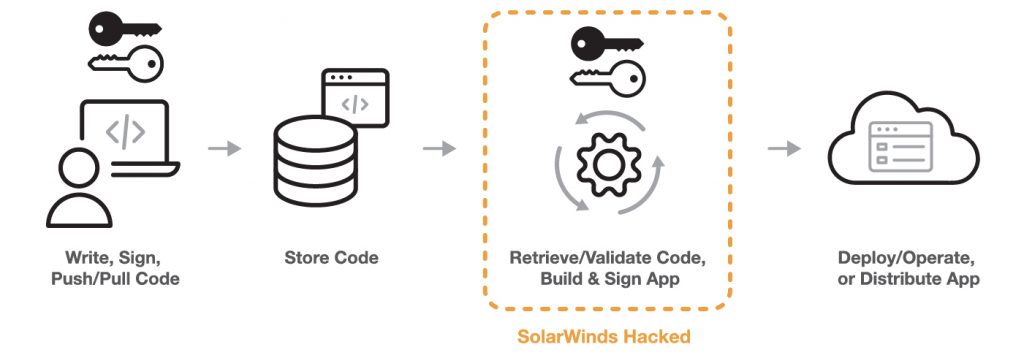
Each trojaned instance of Orion then made connections to the internet using domain names specific to the victim, which were pointed to command and control servers hosted in the same countries as their victims. Those connections served as the basis of the control plane for this malware, and are where the instructions originated for what “bad things” to do next.
Lateral movement and escalation of privilege
Once the attackers were inside the networks of their target organizations, by way of Orion or other means, they leveraged other systems as necessary to gain additional privileges.
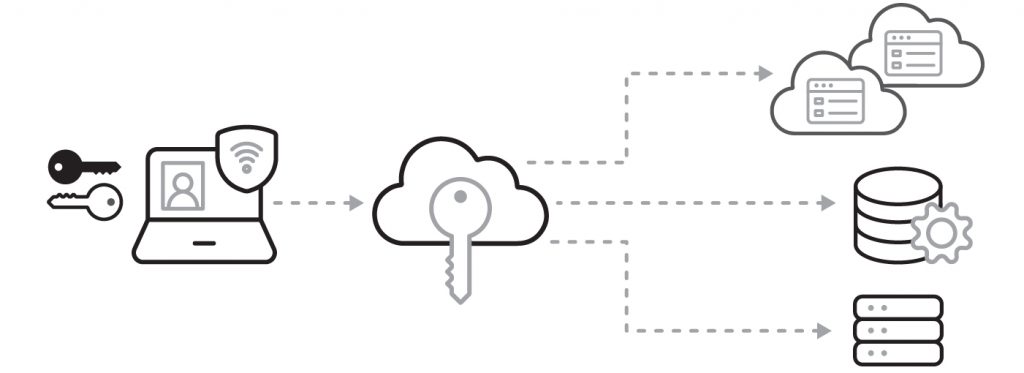
Of note is the supposed misuse of Identity and Access Management (IAM) systems like single sign on, network logon systems, SAML/OAuth/OIDC federation systems, and the like. In particular, there is talk, but not yet persuasive public evidence, that now patched vulnerabilities in Microsoft Netlogin, VMWare Access or Identity Manager, and similar were used to elevate privileges. These systems are also trusted, by necessity, because they convey who is accessing a service by digitally signing an assertion of their validated identity. Attackers would be able to forge assertions if they stole or added keys used to digitally sign assertions.
In this diagram, a user proves their identity to the IAM component in the middle, which then uses its key to sign a message that the services on the right can use to validate that identity. This message contains information about the user accessing the service, and sometimes the roles and privileges that user should be granted.
Persistence and ongoing espionage
As is typical, once the attacker has initial access to the victim’s environment, they diversify their access to help maintain a persistent foothold. Methods will often mirror expected user behavior to reduce the risk of detection. This can include the use of stolen credentials and use of remote access technologies like VPNs.
Specific examples of these tactics include stealing the SAML signing secrets, SSO application integration secrets, or other keys from IAM components that could allow already-obtained access to be utilized without requiring ongoing use of malware on the victim’s network.
Lessons Learned
Develop an inventory and dependency map
The most important thing security professionals can do to secure any environment is to know what they have, where it is, how it’s configured, and what it depends on. In short, it is imperative to have an inventory and a dependency map for your systems and services. While this won’t stop an attacker, it is required to understand what you’re protecting, who and what can access it, and when something does go wrong, what the “blast radius” is. Don’t forget about where your systems could have an impact on your customers!
Once you have identified your most important and/or sensitive assets, you can focus on ensuring you are comfortable with how they, and the access to them are maintained, the people who have access, and the full map of dependencies that can lead to their compromise. Tabletop exercises about breaching specific targets can be quite illuminating here. The MITRE ATT&CK database of adversary techniques gives a great set of angles to consider.
Plan to be breached
In any environment of sufficient value or complexity, the likelihood of something being breached increases over time.. This doesn’t mean we shouldn’t protect our systems! It means we should plan on reducing the opportunity an attacker has to do bad things once they gain access. We do this by having rigorous detection, response, and remediation capabilities.
NIST provides great high-level guidance on much of this process in their cybersecurity framework. Additionally, Microsoft’s security rapid modernization plan is tailored to thinking through these issues and using technology to implement strong, usable solutions on Windows networks.
Mature security practices will include scenario-based drills that exercise detection, response, and remediation processes. They will also include formal debriefs about how effective current practices are and plans to improve them.
Avoid bad advice
The pieces of bad advice I’ve seen the most as part of this particular incident are fortunately few and not pervasive, but are listed below out of an abundance of concern.
First is the idea that you should delay patching. This ensures that any security vulnerabilities patched may be exploitable in your environment for a longer period of time. We’ve seen automated exploit development from publicly patched vulnerabilities in timeframes as short as a day, so this is not usually a great tradeoff. For the most part, organizations lack the ability to evaluate a patch for stability, let alone security, so exercising the muscle of deployment and rollback is the way here. There may be limited environments and organizations where this isn’t true, but those professionals already know what they’re doing and aren’t taking advice from this blog.
The second bad advice I’ve seen is shifting all your time and effort toward your, or your vendors’, supply chains. You should of course make sure you believe the stories you’re told from the things that have the most access to your environment, and that the company telling you these things has a credible team and a good track record. But your time is better spent controlling blast radii and planning for being breached as mentioned above.
Finally, is the idea that you have to immediately move to build and host everything yourself. Business is about risk, and most companies can’t afford to hire the number, and quality, of people who could make this happen. Even if they could, they would not benefit from lessons learned across the industry if they’re only working on your environment. While the most sensitive environments may require deep expertise, custom hardware or software, and very carefully constructed, air gapped environments, most environments will not. Instead, choose vendors carefully, and understand what systems those solutions should and shouldn’t be used for.
Deploy processes and technologies that can help
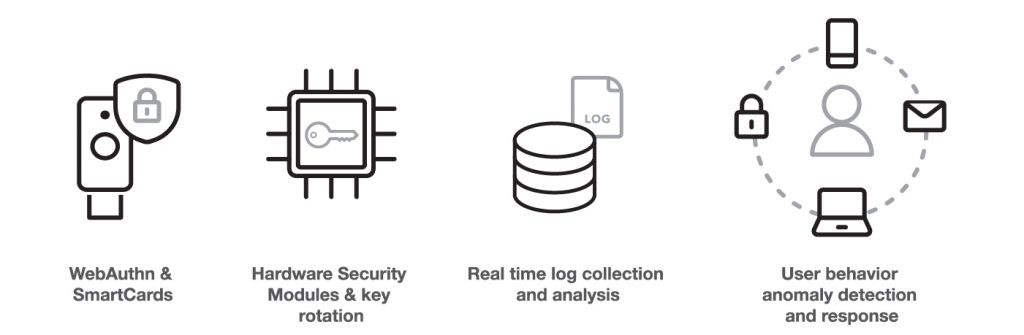
In every breach, assume that capable adversaries will be very knowledgeable about the technologies you use, and will go after the systems that give them the most access to the things that are most valuable to them. Our goal is to detect when that happens and try and make their job as noisy as possible so we can spot them, and get them out quickly. Below are some examples of technology that can help with the techniques we’ve seen so far in this operation.
Private Keys
In each of our previous diagrams you’ll notice icons representing keys in places where they are commonly used, and thus also at risk from being abused. In the SolarWinds campaign and in almost every breach you’ll find credentials, keys, and secrets abused anywhere they can be. The goal of the first two technologies is not to completely prevent abuse of those keys, but rather to ensure that if they are abused, that abuse happens only on or through the systems to which they are attached, at the time that they are attached to them. This allows you the opportunity to monitor your most critical secrets every single time they are used.
WebAuthn and SmartCards replace user passwords and OTP or SMSs with strong hardware-bound public/private key cryptography. This means an attacker can’t walk away with those secrets, and in the case of WebAuthn even requires the user to physically interact with their authenticator every time the key is used. This makes more “noise” and thus allows more opportunity to detect misuse even if the system to which the device is attached is compromised.
HSMs can keep your federated identity systems’ or your build systems’ signing keys from being removed from the environment, and thus monitorable in the same way.
Both of these technologies are critical to use not just for internet-facing services, but also for systems that are “behind the firewall”, because as we’ve seen, it is prudent to assume that someone is always behind your firewall. This forms the basis of a beyondcorp architecture that implements least privilege for all systems. While it may be a long road for many complex environments to get there completely, starting with the most sensitive systems as soon as possible has a very high return on investment.
Logs and Log Analysis
The timeline of this operation was long. If someone called you today and said a threat actor breached your network 9 months ago, would you have the logs you needed to confirm this and track the breach to its origin and across your network as it was explored? Ensuring you have the right logs, the right log retention, and the right processes to keep the attackers from erasing or modifying those logs even as they gain elevated access to your environment is a must. Without that you couldn’t confirm a report of a breach, let alone detect one.
The infected version of Orion couldn’t be remotely controlled unless it could talk to its command and control servers on the internet. Any form of internet access for systems with privileged access to your environment should be tightly controlled. Don’t forget less obvious routes to the internet, like dns tunneling. Allowed access should be monitored and logged, and unusual or new behavior scrutinized by experts.
One tricky bit about logs is that, all too often, alerts are set up only for an event happening rather than for an event not happening. In the case of the misuse of IAM signing secrets above, the system which was accessed using a SAML assertion for a given user would have logged that, but the IAM system would not have logged it, and that discrepancy could have detected the misuse right away.
Behavioral modeling and anomaly detection
It turns out that FireEye caught this attack because of MFA logs and alerting which informed an employee and their security team that someone added a new device to the employee’s account that they didn’t recognize. Many large breaches have been detected by attentive employees. Striking the right balance of alerting, not just for the security team but also for employees, is key. Too much, and they’ll be ignored; too little, and they won’t have the opportunity to notice.
Technologies that build profiles of user or system behavior and alert the user or a security administrator of unusual behavior have come a long way, and deploying them in a transparent and focused manner can help us leverage our entire organizations to get better at detection and response.
Parting Thoughts
While there is no silver bullet to prevent this sort of attack, there are many well established practices and technologies that can help ensure we compartmentalize any damage, detect breaches quickly, and respond and recover before the adversaries get too far.
We hope this was helpful, and don’t hesitate to reach out to Yubico if you need help or have questions about using our solutions to address these sorts of campaigns.
And if you’re interested, please join us for an upcoming webinar on January 19, “Securing privileged accounts and critical authentication resources”. We’ll cover the basics of securing administrator access, best practices for enrolling YubiKeys for smart card administration, and methods for enrolling YubiKeys as security keys for administrators.
Merry Christmas, Happy Holidays, God Jul, och Gott Nytt År,
Christopher Harrell
CTO, Yubico


